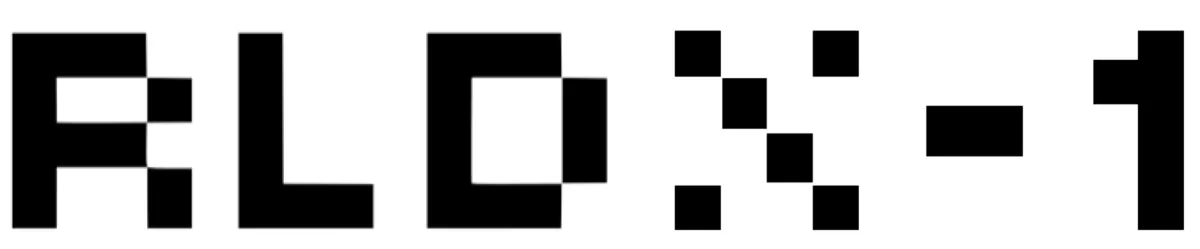
Real World Unveils Japan's First Robotics Foundation Model 'RLDX-1' for Advanced Physical AI




Real World Unveils RLDX-1: Pioneering Robotics Foundation Model
On May 7, 2026, Real World Corporation (RLWRLD) formally introduced 'RLDX-1', its unique Robotics Foundation Model (RFM) designed for cutting-edge developments in physical AI. This model revolutionizes traditional AI paradigms by integrating not only visual and linguistic capabilities but also tactile feedback, force detection, and working memory within a single framework. RLDX-1 uses a 'Dexterity-First' design concept, radically departing from conventional Vision-Language-Action (VLA) models that primarily focus on visual cues.
A New Approach to Dexterity
Traditionally, the prevailing belief has been that once intelligence is established, dexterity will naturally follow. However, RLWRLD challenges this notion, asserting that dexterity is not an ancillary result of intelligence but a fundamental component necessary for intelligent behavior in the physical world. By processing signals such as torque, tactile feedback, and contact timing—elements that visual information alone cannot capture—RLDX-1 aims to automate precise tasks in industrial environments.
To validate this premise, RLWRLD has proactively engaged with real-world manual labor challenges, establishing a systematic benchmark called 'DexBench.' This benchmark quantitatively evaluates dexterity through five key dimensions: 1) Grasp Diversity, 2) Spatial Precision, 3) Temporal Precision, 4) Contact Precision, and 5) Context Awareness.
Superior Performance on Global Benchmarks
RLDX-1 has demonstrated exceptional capabilities, outperforming existing state-of-the-art models such as NVIDIA's GR00T and Physical Intelligence's πO in eight prestigious global benchmarks. Particularly noteworthy is its score of 70.6 in the 'RoboCasa Kitchen' benchmark, indicating a significant achievement for VLA models. In a humanoid-specific evaluation known as 'GR-1 Tabletop,' RLDX-1 secured a score of 58.7, maintaining a leading position over competing models.
Moreover, in dynamic environments utilizing the WiRobotics-developed humanoid 'ALLEX', RLDX-1 achieved a 70.8% success rate in a challenging 'Pot-to-Cup Pouring' task, a doubling of success compared to competing models, which lingered in the low 30% range.
The Core Architecture: Multi-Stream Action Transformer (MSAT)
The backbone of RLWRLD's technology is the Multi-Stream Action Transformer (MSAT). Unlike traditional VLA models that process various signals through a single stream, MSAT employs separate streams for each modality, enabling joint attention across modalities. This architecture adeptly integrates non-visual physical signals and long-term memory through dedicated modules (Physics and Memory Modules), facilitating a continuous cycle of 'seeing, feeling, remembering, and adapting'.
CTO of RLWRLD, Pe Jae-kyung, emphasized, "The separation of structures allows each modality to fully express its characteristics, crucially capturing torque signals during contact moments and inferring dynamic changes over time—areas traditionally challenging for VLA models."
Collaboration with Major Korean and Japanese Firms
Another critical aspect of RLDX-1 is its design tailored for practical industrial applications from the outset. RLWRLD has collaborated with numerous industry partners to analyze real-world factory operations, directly feeding this information into their self-developed 'DexBench' benchmark, aligning it closely with industry needs. Key collaborators include major companies like SK Telecom, LG Electronics, CJ Korea Express, Lotte, KDDI, ANA Holdings, Mitsui Chemicals, and Shimadzu Corporation. RLWRLD aims to establish DexBench as an industry standard for dexterity assessments.
Building an Ecosystem Centered on RFM
At the upcoming




Topics Other)


【About Using Articles】
You can freely use the title and article content by linking to the page where the article is posted.
※ Images cannot be used.
【About Links】
Links are free to use.