Hitachi Launches Enhanced HADB 6: A Game Changer for Data Lake House Applications




Hitachi Unveils Improved HADB Version 6
On October 1st, Hitachi Limited announced the launch of the latest version of its high-speed database engine, Hitachi Advanced Database (HADB) version 6. This innovative release aims to facilitate the utilization of diverse data within data lake house environments.
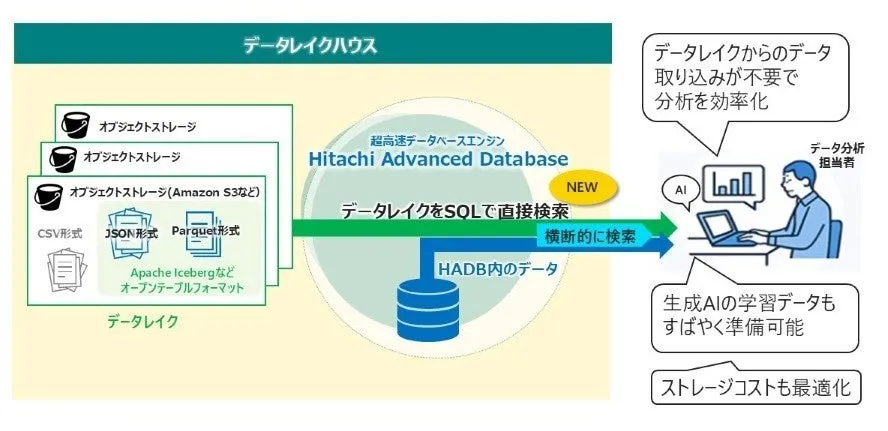
With the new version, users can directly query various data stored on object storage systems, such as Amazon S3, using SQL. This capability allows data analysts to bypass the need for preprocessing or importing data into HADB, enabling cross-sectional searches and analyses that combine data from both the database and the data lake.
Enhancing Service Creation and Efficiency
The newfound flexibility aids companies in generating new services by providing multi-faceted analyses using a mix of different data. Additionally, when it comes to applying generative AI in businesses, HADB 6 allows for prompt searches of extensive datasets within data lakes, streamlining the preparation of substantial training data to enhance AI learning efficiency.
Another highlight of HADB is its support for parallel processing based on non-sequential execution principles. This feature compensates for the typically slower data read speeds associated with object storage, thus guaranteeing rapid data searches. Users can enjoy the best of both worlds: utilizing affordable object storage while achieving data analysis speeds comparable to those of conventional data warehouses.
New Licensing Model for Cost Optimization
Unlike typical cloud services that charge based on the volume of data queried, the latest version of HADB offers a new licensing option. In addition to the traditional capacity-based model, users can now choose a flat-rate license that permits searches across data lakes without any capacity restrictions. This innovation aims to optimize storage costs while ensuring efficient data access.
Hitachi has promised to strengthen its on-premises data lake solutions by introducing the Amazon S3-compatible object storage system, Hitachi Virtual Storage Platform One Object, by 2025. This development is expected to enhance the capabilities of HADB for on-premises data lakes and advance toward more sophisticated search techniques, including support for vector data and graph structures that account for data significance and attributes.
Background of HADB Evolution
The importance of leveraging data has surged in recent years as businesses aim to innovate services and boost operational efficiency through generative AI. Data analysts often analyze vast amounts of diverse data repeatedly from multiple perspectives to derive new service ideas. The typical approach involves using an object storage-based data lake to house extensive data sets. However, the necessary preprocessing and importing of data into databases often burden analysts.
In response to this need, Hitachi has implemented the non-sequential execution principle into HADB to enable ultra-fast analysis of complex datasets, applying the technology across various sectors including manufacturing, distribution, finance, social, and public domains. By releasing the latest version of HADB, the company intends to expedite digital transformation initiatives by allowing seamless and rapid data searches across external data lakes in addition to data warehouses.
Key Features of HADB Version 6
The latest release enhances direct querying capabilities of SQL on files and open table formats stored on object storage. Users can effortlessly run queries on CSV, JSON, Parquet data, and Apache Iceberg tables stored on Amazon S3 without any preprocessing or importing steps. Moreover, HADB's unique execution principle ensures that even though object storage may have slower read speeds, parallel processing allows for efficient and speedy searches. Results from these queries can be output as Parquet files on object storage, making it easier for data scientists to utilize them in large-scale analysis workflows and machine learning pipelines.
Use Cases and Benefits
1. Diversifying Data Analysis: With services like HADB, companies can consolidate their analysis of historical and purchase data seamlessly without any preprocessing hurdles. This facilitates extensive insights into past and present data through cross-sectional queries, enhancing validation and prediction processes.
2. Accelerating Generative AI Applications: When leveraging data from data lakes for generative AI training, HADB processes raw structural data directly, allowing for a swift transition to Parquet format without extensive preprocessing. This accelerates data preparation and enhances the overall learning efficiency of generative AI applications.
3. Optimizing Data Storage and Search Capability: By enabling the fast search capabilities of data on object storage, HADB allows organizations to selectively store less frequently accessed data in cost-effective data lakes while keeping highly utilized data in the database for quick access. This stratification can lead to significant cost savings on storage while ensuring that data can be retrieved promptly when necessary, such as during audits.
Pricing and Availability
| Product | Overview | Standard Price | Available From |
|---|---|---|---|
| -------- | --------- | ----- | ------ |
| Hitachi Advanced Database Version 6 | Direct SQL querying on external data lakes | Annual Subscription: ¥3,834,000 and up | October 1 |
Topics Consumer Technology)
【About Using Articles】
You can freely use the title and article content by linking to the page where the article is posted.
※ Images cannot be used.
【About Links】
Links are free to use.